언젠가 누군가에게 이런 질문을 들었던 기억이 있다. “브라우저 URL 입력창에 ‘www.google.com’을 입력하면 어떤 일이 일어날까요?” 당시에는 별생각 없이 넘겼지만, 최근 들어 이 질문이 웹 기술 전반에 대한 깊은 이해를 평가하기 위한 면접 질문으로 자주 활용된다는 사실을 알게 되었다.
처음엔 단순한 질문처럼 느껴졌지만, 자세히 들여다보면 브라우저, 네트워크, DNS, HTTP, 렌더링까지 다양한 기술이 유기적으로 작동하는 과정을 담고 있다는 점에서 매우 흥미롭고, 의미 있는 질문이라는 걸 깨달았다. 그래서 이 좋은 질문을 주제로 블로그 글을 작성해보려 한다.
브라우저는 Domain에 해당하는 IP를 찾는다
DNS(Domain Name System)는 웹사이트의 도메인 이름과 해당 서버의 IP 주소를 매핑해주는 데이터베이스이다. 모든 URL은 고유한 IP 주소와 연결되어 있으며, 이 IP는 실제 웹사이트가 호스팅되고 있는 서버 컴퓨터를 가리킨다. 예를 들어 www.google.com의 IP 주소는 172.217.31.5와 같은 형태일 수 있다.

따라서 사용자는 브라우저 주소창에 https://172.217.31.5를 입력해도 구글에 접속할 수 있지만, 사람이 이해하고 기억하기에는 숫자보다 https://www.google.com과 같은 도메인 이름이 훨씬 쉽다.
이를 위해 DNS가 사용되며, 따라서 사용자가 www.google.com을 입력하면 브라우저는 해당 도메인에 대한 IP 주소를 찾기 위한 과정을 거치게 된다.
4개의 Cache에서 IP 찾는다
브라우저는 위에서 www.google.com에 해당하는 DNS 레코드를 찾기 위해 4개의 Cache를 확인한다.
| Browser Cache를 확인한다. 브라우저는 이전에 방문한 웹사이트의 DNS 레코드를 일정 기간 동안 유지하고 있다 |
| OS Cache를 확인한다. OS 또한 DNS Cache를 유지하기 때문에 컴퓨터 OS에 시스템 호출을 한다 |
| Rotuer Cache를 확인한다. 컴퓨터 Cache에 남아있지 않다면 자체 DNS 레코드 Cache를 가지고 있는 Router에서 찾는다 |
| ISP Cache를 확인한다. Browser는 ISP에게 요청하여 ISP의 DNS 서버에서 IP를 찾는다 |
캐시에서 IP 주소를 찾지 못하면, 브라우저는 DNS 쿼리를 통해 IP 주소를 찾기 시작한다. DNS 쿼리는 도메인 이름에 해당하는 IP 주소를 알아내기 위해 여러 DNS 서버를 순차적으로 조회하는 과정이다.
이 과정은 단일 서버가 아닌 여러 DNS 서버를 거쳐가며 진행되며, IP 주소를 성공적으로 찾거나, 찾을 수 없다는 응답을 받을 때까지 계속된다. 이처럼 여러 서버를 거쳐가며 반복적으로 조회를 수행하는 방식 때문에 이를 재귀적 검색이라고 부르기도 한다.

이때 사용자의 ISP가 제공하는 DNS 서버는, 다른 DNS 서버로부터 IP 주소를 찾아오는 역할을 맡고 있기 때문에 DNS 리커서라고 불린다. 반면, 실제로 도메인 이름에 대한 정보를 보유하고 있는 다른 DNS 서버들은 네임 서버라고 부른다.
먼저 DNS 리커서는 인터넷의 최상위에 위치한 루트 네임 서버에 요청을 보낸다. 이 루트 서버들은 미 국방부, NASA, ICANN, WIDE 등 특정 기관들이 운영하고 있으며, 이 서버들은 TLD(Top-Level Domain) 서버의 위치를 알려주는 역할을 한다.
예를 들어, 사용자가 www.google.com 도메인을 요청하면, 루트 네임 서버는 .com 도메인을 관리하는 TLD 네임 서버의 위치를 리턴해준다. 그 다음 DNS 리커서는 .com TLD 서버에 다시 요청을 보내고, .com 서버는 google.com 도메인을 관리하는 권한 네임 서버의 위치로 리다이렉션을 한다.
최종적으로 google.com 도메인을 관리하는 네임 서버는 자신의 DNS 레코드에서 www.google.com에 해당하는 IP 주소를 찾아 응답하게 된다. 이렇게 여러 단계에 걸쳐 요청과 응답이 이어진 끝에, 브라우저는 www.google.com의 IP 주소인 172.217.31.5를 얻을 수 있게 된다.
목적지 IP로 패킷을 전달한다
브라우저가 www.google.com의 IP 주소인 172.217.31.5를 알아내면, 해당 목적지로 데이터를 전송하기 위해 라우터가 동작한다. 라우터는 패킷을 목적지까지 효율적으로 전달하기 위해 라우팅 과정을 수행하며, 이를 위해 총 세 가지 주요 테이블을 활용한다.
이 테이블들은 라우터가 네트워크에 연결된 다양한 장치들의 주소를 파악하고, 어떤 경로로 패킷을 전송할지 판단하는 데 사용된다. 이러한 정보를 바탕으로 라우터는 패킷이 172.217.31.5로 향할 수 있도록 올바른 경로를 설정하고, 중간에 위치한 여러 네트워크 장치를 거쳐 최종적으로 구글 서버에 도달하게 만든다.
| 랜테이블을 확인하여 패킷의 목적지가 같은 네트워크인지, 다른 네트워크인지 검사한다 |
| 네트워크 테이블을 확인하여 패킷을 전달한 네트워크 주소를 찾는다 |
| 라우팅 테이블을 확인하여 적합한 경로를 찾아서 패킷을 보낸다 |

목적지 MAC 주소를 알아내기 위한 ARP 과정
라우팅 테이블을 통해 목적지 IP로 가는 경로가 결정되었다면, 실제로 패킷을 전송하기 위해서는 목적지 MAC 주소가 필요하다. 네트워크 상에서 데이터는 IP가 아니라 MAC 주소 기반으로 전송되기 때문이다. 이때 사용되는 프로토콜이 바로 ARP(Address Resolution Protocol)이다.
참고로MAC 주소는 네트워크 카드(NIC)에 할당된 고유 식별자
→ 쉽게 말하면 "네트워크 장치의 주민등록번호" 같은 거
ARP는 목적지 IP 주소에 해당하는 장치의 MAC 주소를 알아내기 위해 네트워크에 브로드캐스트 요청을 보낸다. 같은 네트워크에 있는 장치 중 IP가 일치하는 대상만이 자신의 MAC 주소를 응답으로 보내주며, 이 정보를 바탕으로 패킷은 전송될 수 있게 된다. 이 과정을 통해 MAC 주소를 알아낸 후에야, 실제 TCP 연결 요청(SYN 패킷)을 상대에게 보낼 수 있다.

브라우저와 서버의 TCP 연결 시작한다

서버와 안정적인 통신을 시작하려면 먼저 TCP 연결을 수립해야 한다. 이때 사용하는 방식이 바로 TCP 3-way handshake로, 클라이언트와 서버가 세 번의 메시지를 주고받으며 서로 연결 상태를 확인하고, 신뢰할 수 있는 연결을 형성하는 과정이다.
먼저 클라이언트는 서버에게 연결을 요청하는 SYN 패킷을 보낸다. 이 패킷에는 클라이언트가 정한 초기 순서 번호(Sequence Number)와 수신 가능한 데이터 크기를 의미하는 윈도우 크기 정보가 포함되어 있다.
서버는 이 요청을 수락하면, 클라이언트에게 SYN과 ACK 플래그가 모두 설정된 응답을 보낸다. 여기에는 서버 측의 초기 순서 번호와 함께, 클라이언트가 보낸 순서 번호에 대한 응답으로 ACK 번호가 포함된다.
마지막으로 클라이언트는 서버의 응답을 확인하고, ACK 플래그가 설정된 패킷을 서버에 다시 보낸다. 이 ACK 패킷에는 서버의 순서 번호에 대한 응답이 담겨 있다. 이 세 번째 메시지가 도착하면 비로소 연결이 완전히 설정되고, 본격적인 데이터 전송이 시작될 수 있다.
브라우저와 서버의 TLS Hand shaking을 시작한다

클라이언트는 서버에게 "client hello"를 보내는 것으로 hend shaking를 시작한다. 서버는 클라이언트에게 자신을 검증할 수 있는 정보들을 보낸다
| "server hello" 클라이언트에게 보내는 메시지 |
| "certificate" 서버의 인증서와 서버의 공개키 |
| "server Hello done" 전달할 정보 끝 |
클라이언트는 서버와 통신할 때 사용할 대칭키를 만들 수 있는 값인 pre-master-secret를 "client key exchange"를 통해 전달한다.
클라이언트는 이 handshake에 의해 정해진 암호 방식을 적용하겠다고 "change cipher Spec"를 통해 알린다. finished를 통해 서버에게 handshake 가 종료됨을 알린다.
서버도 이 handshake에 의해 정해진 암호 방식을 적용하겠다고 "change cipher Spec"를 통해 알린다. finished를 통해 클라이언트에게 handshake 가 종료됨을 알린다.
브라우저는 웹 서버에게 HTTP 요청을 보낸다
브라우저와 서버의 모든 연결이 끝났기에 데이터 전송을 시작한다. 브라우저는 www.google.com에 대해 GET 요청을 보내게 된다.
서버는 HTTP 요청을 처리한다

요청을 받을 컨트롤러에게 위임한다. 스프링의 경우 dispatcher servlet 가 http 프로토콜로 들어오는 요청을 받아 요청을 위임할 적절한 controller(handler)를 찾아 요청을 한다.
아래의 코드를 보면 HTTP Mothod에 따라 do 메서드를 호출하고 요청에 매핑되는 Handler을 조회한 후에 Handler를 수행할 수 있는 adapter을 조회해서 실제 controller을 호출하는 과정을 찾을 수 있다
DispatcherServlet.java
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String method = req.getMethod();
//생략
if (method.equals(METHOD_GET)) doGet(req, resp);
else if (method.equals(METHOD_HEAD)) doHead(req, resp);
else if (method.equals(METHOD_POST)) doPost(req, resp);
else if (method.equals(METHOD_PUT)) doPut(req, resp);
else if (method.equals(METHOD_DELETE)) doDelete(req, resp);
else if (method.equals(METHOD_OPTIONS)) doOptions(req,resp);
else if (method.equals(METHOD_TRACE)) doTrace(req,resp);
//생략
}
HandlerAdapter.java
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerExecutionChain mappedHandler = null;
//생략
mappedHandler = getHandler(processedRequest);
//생략
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
//생략
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
//생략
}
서버는 요청에 대한 처리를 수행한다
@Controller @Service, @Repository 어노테이션에 의해 스프링 컨테이너에게 관리되어 있는 빈 객체들을 사용하여 요청에 대한 비즈니스 로직을 수행한다.
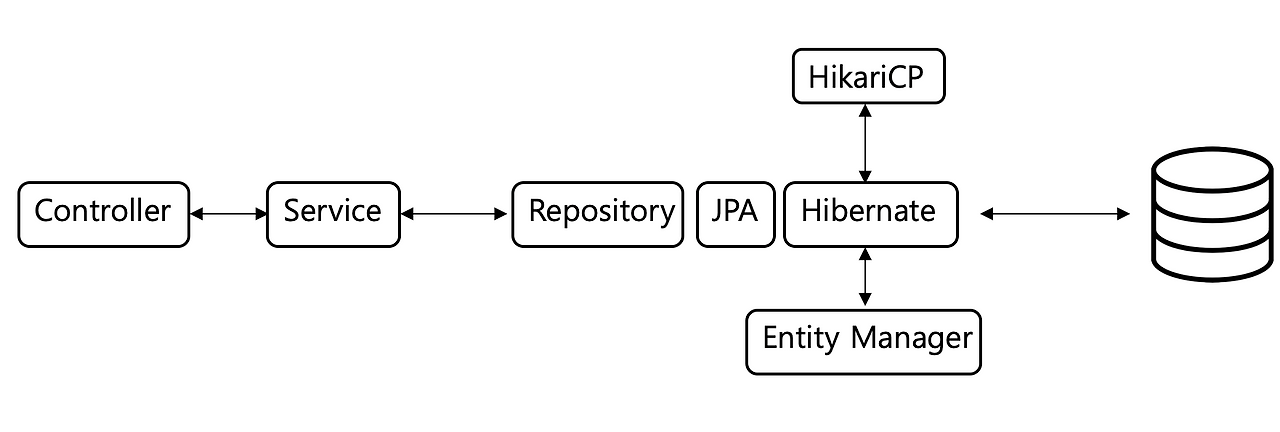
스프링 기반 애플리케이션에서 Controller는 @RequestMapping 등의 어노테이션에 의해 Handler Mapping에 등록되며, HTTP 요청의 진입점 역할을 수행한다. 클라이언트의 요청을 받아 적절한 응답을 반환하며, 실제 비즈니스 로직 처리는 주로 Service 계층에 위임한다.
Service는 Controller로부터 전달받은 요청이나 다른 서비스로부터 위임받은 작업을 처리하며, 핵심 비즈니스 로직을 담당한다. 일반적으로 @Transactional 어노테이션을 통해 트랜잭션의 시작과 종료 시점을 관리하며, 안정적인 데이터 처리를 보장한다. Repository는 데이터베이스 접근을 전담하는 계층이다.
Spring Data JPA를 사용하는 경우 내부적으로 EntityManager를 통해 데이터베이스와 통신하고, 이 과정은 JPA의 구현체인 Hibernate에 의해 처리된다. Hibernate는 다시 JDBC를 통해 실제 데이터베이스와 연결되며, 이때 DB 커넥션 풀 관리 도구로는 보통 HikariCP가 사용된다. 이처럼 각 계층이 명확하게 역할을 분담함으로써, 클라이언트의 요청을 효율적으로 처리하고 유지보수하기 쉬운 구조를 갖출 수 있다.
서버는 화면을 만들어서 전달한다

Controller 가 다른 계층에서 얻은 데이터를 가지고 만든 Model을 가지고 View Resolver와 함께 사용자에게 보여줄 View를 만들어서 반환한다

브라우저는 HTML을 랜더링 한다

브라우저의 구조는 간단히 요약하면, 서버로부터 전달받은 HTML과 CSS를 파싱하고 이를 기반으로 화면에 내용을 그리는 일련의 과정을 수행하는 형태로 이루어져 있다. 먼저, 브라우저는 받은 HTML을 파싱하여 DOM(Document Object Model) 트리를 생성한다.
이와 함께 HTML 안에 포함된 CSS를 파싱하여 CSSOM(CSS Object Model) 트리를 만든다. 그 다음, DOM 트리와 CSSOM 트리를 결합하여 렌더 트리를 구성한다. 이 렌더 트리는 실제 화면에 표시되어야 할 요소들의 구조와 스타일을 반영한다.
이후 레이아웃 단계에서는 각 요소의 위치와 크기를 계산하고, 페인팅 단계에서는 계산된 정보를 바탕으로 각 요소를 픽셀 단위로 변환한다. 마지막으로, 이 렌더링 결과가 화면에 그려지며 사용자는 브라우저를 통해 웹페이지를 시각적으로 확인할 수 있게 된다.

'CS' 카테고리의 다른 글
| Redis가 싱글 스레드로 만들어진 이유 (2) | 2025.06.05 |
|---|---|
| MySQL InnoDB에서 갭락과 넥스트키 락이란 무엇이며, 어떻게 팬텀 리드를 방지하나요? (0) | 2025.05.29 |
| equals()와 hashCode() 재정의 (1) | 2025.05.22 |
| 블로킹 vs 논블로킹, 동기 vs 비동기 (0) | 2025.05.10 |
| 외부 서비스 장애에 대비하는 백엔드 설계 전략 (0) | 2025.05.08 |



